<< Back By Panda-Admin | July 1, 2024
Inside a Torrents Tracker bot V2

Intro
This is the second version of an old post about how our bot is organized internally. You can compare the old bot scheme with the new one and see the recent changes. The expansion of functionality has influenced the application structure and the bot's operation.
Python 3.12 is chosen as the main programming language. To work with some libraries, such as libtorrent, Python 3.10 is required, as it is the latest version supported by this library. However, we have our own build of the latest version of this library for Python 3.11 and 3.12, but it is not yet used due to Python version limitations in the Serverless function of the Scaleway service.
Below is a diagram showing how everything is organized on the server side of the bot at the moment.
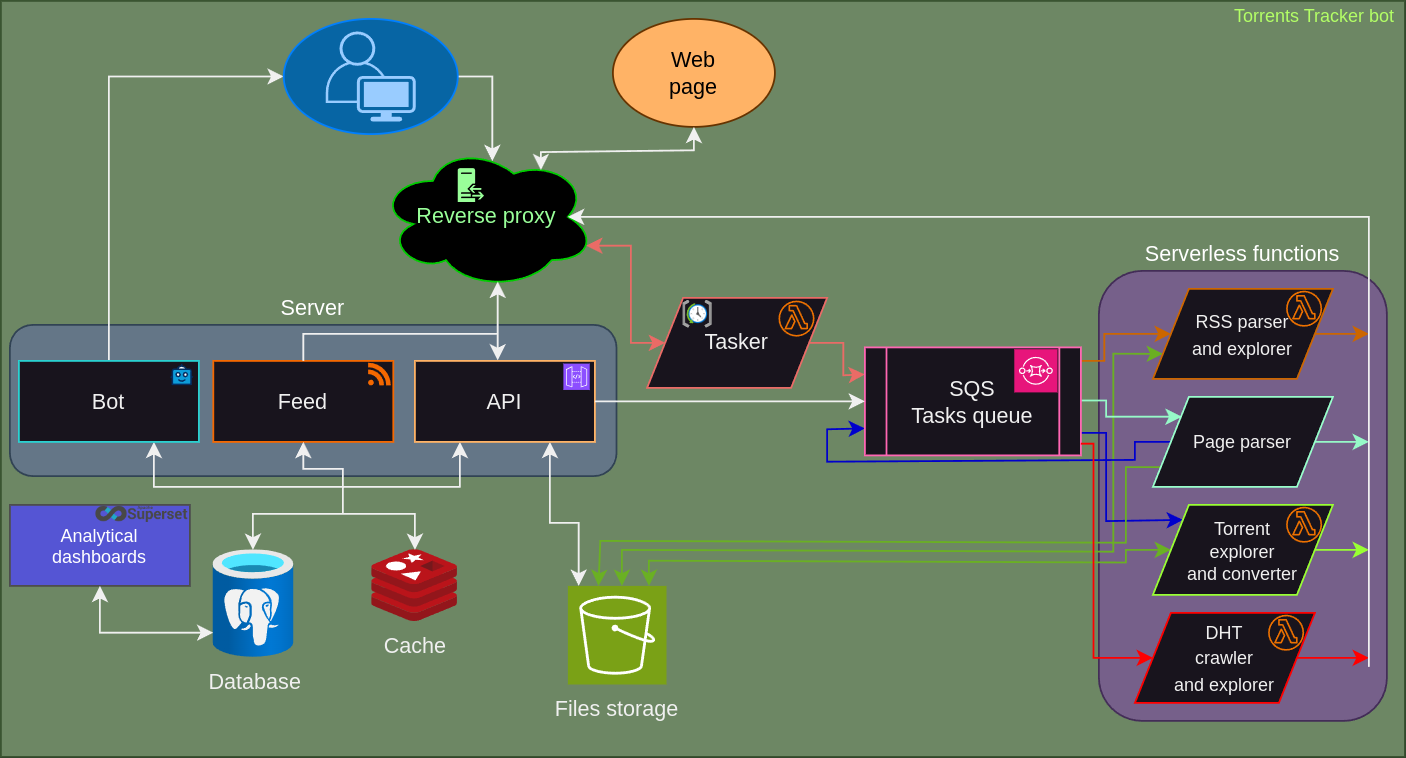
Schema description
For interacting with Telegram, we use a callback approach. After starting the bot service, it registers a domain name on the Telegram server. Our domain is red-panda-dev.xyz, with a subdomain for easier access. When a user starts the bot or executes any command, a POST request with user action information is sent to the registered address. This request first hits the reverse proxy, which is managed by Nginx.
Nginx, based on its configurations, forwards the request to the API service. We use Flask for the API service, a reliable and time-tested microframework. The API service verifies the request, serializes it, and passes it to the Telegram bot's task queue. For interacting with Telegram bot APIs, we use the aiogram library. It allows for easy bot management, maintaining user dialogue states, and is actively supported by the community.
The bot logic processes the received message, finds the corresponding command logic, executes it, and if necessary, interacts with the database or creates a task, such as processing a torrent file link. When a user starts interacting with the bot, their information is added to our PostgreSQL v16 database. The database stores user IDs, enabling the bot to initiate message sending and link torrent files to specific users.
Various additional data is stored in the cache using Redis. Specifically, it holds data about the user's dialogue state and their recent bot activities. For handling deferred tasks, serverless functions are set up and running. These functions receive information from the task queue, which the main server sends. The task queue uses SQS.
In some tasks, saving torrent files for subsequent processing is required, and for this purpose, an S3-like storage is used. It provides fast access and unlimited storage capacity for files.
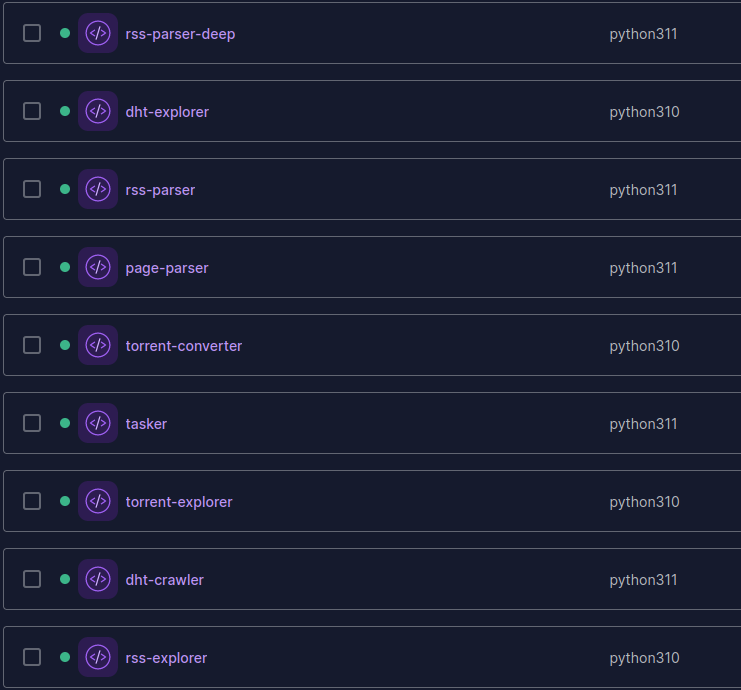
Serverless functions
The main tasks of gathering information about torrents, parsing sources, and the network are handled by Serverless functions. All functions are written in Python 3.10 - 3.11. This is an affordable, scalable, and easily configurable tool. Similar services are available from all major cloud providers.
The main task initiator is Tasker, a function that runs on a schedule every N hours and creates trigger messages for other functions. The remaining functions are triggered by messages from the SQS queue, where they also receive the main data for their work. If the data for the task is insufficient, the function queries the main API for additional data, such as a proxy address, User-Agent for the header, etc.
Functions and their tasks:
- RSS Parser: Parses RSS feeds and updated pages with fresh torrents (if RSS is absent).
- RSS Explorer: Extracts torrent metadata from the network, runs a torrent client, and provides magnet-link or torrent information.
- Page Parser: Downloads torrents from pages when a user adds them for tracking, stores them in the database, and another function compares the new torrent data with the previous version, notifying the user of any updates.
- Torrent Explorer: Checks tracked torrents, retrieves metadata, and sends it to the backend.
- Torrent Converter: Converts torrent files or magnet-links provided by the user into both formats.
- DHT Crawler: Collects addresses and hash indexes of torrents in the DHT network, sending the data to the backend for storage and further processing.
- DHT Explorer: Retrieves previously found hash indexes and IP addresses, attempting to download torrent metadata from them.
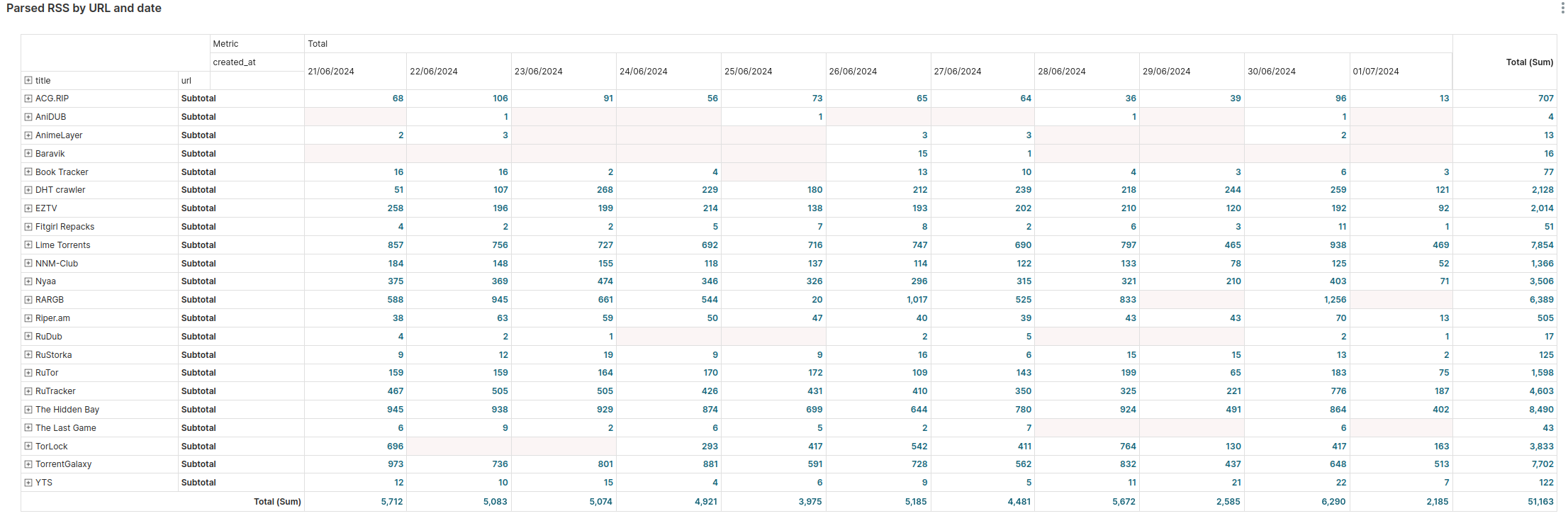
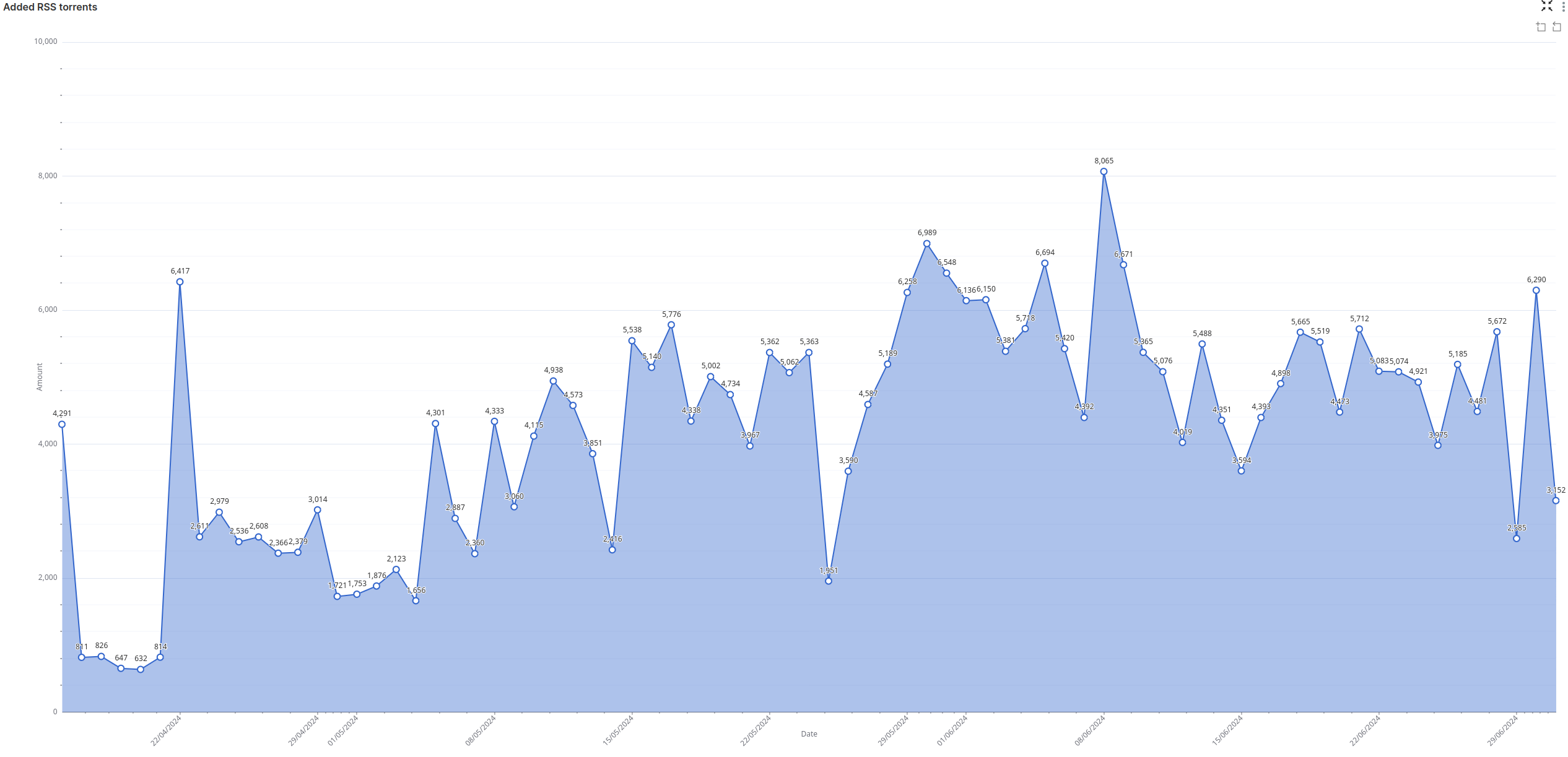
Analytical Dashboards
A completely new module in the system is the dashboard with analytics and bot function statistics - Apache Superset. This is a flexible and powerful tool for visualizing data stored in the database. The visualized data allows for a better understanding of the parsers' performance and user activity when working with various bot functions.
Web page
We previously wrote about adding web search, here's how it works:
After adding a torrent to the database, all special characters and various junk (some trackers automatically add to their torrent names) are removed from its name. The cleaned string is saved in a separate column in the database and is then searched using trigrams. For better user experience, results are sorted by the degree of match between the query string and the string in the database. The similarity degree is determined using the strict_word_similarity function provided by the pg_trgm module.
strict_word_similarity - Returns a number that indicates the greatest similarity between the set of trigrams in the first string and any continuous extent of an ordered set of trigrams in the second string. Forces extent boundaries to match word boundaries. Since we don't have cross-word trigrams, this function actually returns greatest similarity between first string and any continuous extent of words of the second string.
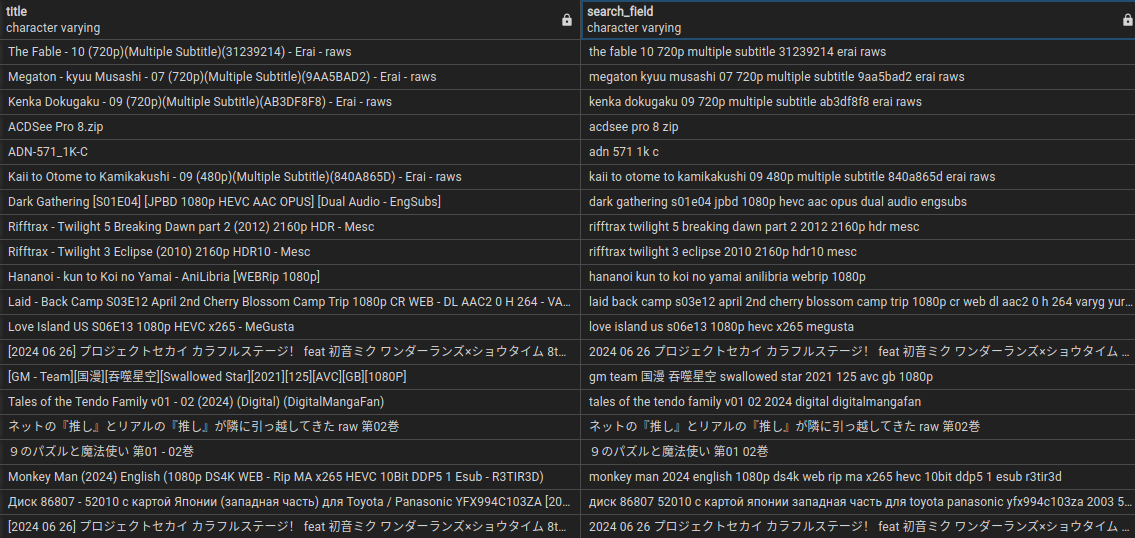
Fin
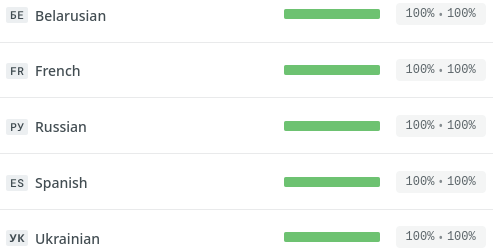
Recently, additional languages have been added to the bot to communicate with the user. Now the bot can answer in 6 languages:
- English
- French
- Spanish
- Russian
- Belarusian
- Ukrainian
For translation we use Crowdin service. And you can help us add more translations or fix existed - click here and take part in translation.
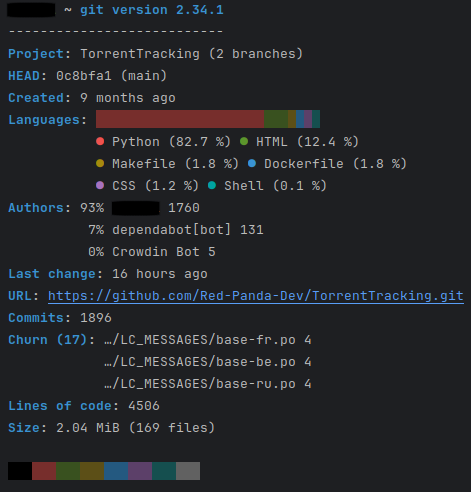
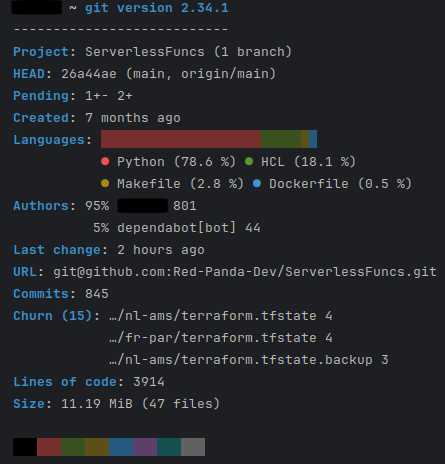
For development we use Git version control and Github to store code base. Here is some statistic from our main repositories. Superset and CMS is not included.
Join our bot today and take your torrenting experience to the next level: @torrents_tracker_bot and try our torrents web search.